Автор: Антон Козицкий
Принцип DRY: не повторяй себя

Одна из лучших практик в разработке программного обеспечения говорит нам:
Любые знания должны быть представлены в одном месте в вашей программе
Но что это означает на практике простыми словами? Давайте посмотрим вместе и на примерах. Но для начала разберёмся, что такое «знания» и как они могут выглядеть на практике.
Итак, что мы можем дублировать:
- Конфигурации могут дублировать друг друга — как в разных файлах, так и в рамках одного файла конфигурации;
- Методы, которые делают ровно одно и то же, могут повторяться в одном и даже более чем одном классе в вашем приложении;
- Части больших методов могут дублировать друг друга, выполняя в точности одну и ту же логику;
- Объявления констант.
На более глобальном уровне дублирование и повторение может быть даже на уровне сервисов, если мы говорим про микросервисную архитектуру. Да, такое бывает — я лично с таким сталкивался в своей практике, когда в разных сервисах есть повторяющийся код. Бывает так по задаче, что в двух или даже больше сервисах нужно иметь одинаковую логику:
- Например, это логика по выполнению запросов к внешним, сторонним сервисам и их последующая обработка. И бывает так, что несколько сервисов делают такие запросы, то есть имеют повторяющийся код;
- Это также может быть логика логирования, которая выглядит одинаково для всех сервисов ради согласованности (консистентности) системы.
Далее мы поговорим о том, почему дублирование — это плохо, а после — о том, как исправлять и по возможности даже не допускать таких проблем в своём коде. Сразу оговорюсь: в коде допускается некоторое дублирование, и здесь нужно чётко понимать, где это допустимо, а где это уже становится (или станет в будущем) проблемой. Чтобы лучше в этом разобраться, мы посмотрим на реальные примеры.
Чем плохо дублирование
Нарушение принципа DRY может создавать такие проблемы:
Поддержка кода становится сложной
Представьте, что у вас есть дублирующийся код — например, конфигурация. В какой-то момент вам по задаче необходимо изменить настройки этой конфигурации. Вы идёте в код и меняете. Но потом выясняется, что приложение работает не так, как нужно. А всё дело в том, что вы изменили конфигурацию в одном месте, но забыли это сделать во втором — потому что и не думали, что она ещё где-то повторяется.
Когда «знания» (в данном случае конфигурация приложения) находятся в одном месте и мы знаем, где это место, мы всегда работаем только с ним. Но когда мы ещё где-то «дублируем» конфигурацию, то каждый раз, когда меняем её, нам нужно сделать это в двух (или более) местах. В этом вся сложность и причина, почему мы можем получать проблемы в будущем.
Под угрозу ставится согласованность логики программы
Или, допустим, у вас в коде есть метод по расчёту скидки на товар. И по стечению обстоятельств он оказался в двух классах:
- в
DiscountService— здесь он был изначально и был добавлен первым разработчиком, впоследствии покинувшим проект; - в
OrderService— новый разработчик просто не знал, что логика по расчёту скидки уже есть в проекте, и написал небольшой приватный метод прямо вOrderService.
Такое поведение, когда у вас два метода, может привести к тому, что разные части кода будут использовать разные методы, смешивая их. Это приведёт к тому, что логика расчёта будет разной. Либо, если оригинальный метод не используется, приведёт к «мёртвому коду» (dead code). «Мёртвый код» сам по себе не опасен, так как не используется, но может приводить к плохим последствиям, если в какой-то момент начнёт использоваться снова.
Ненужные трудозатраты
Вы тратите новые силы, когда пишете код, который уже где-то есть в вашем большом приложении. Его нужно лишь найти и переиспользовать.
Как решать проблему дублирования
Сначала напишу, как лично я решаю эту проблему, а потом дополню общеизвестными практиками.
Следовать практикам написания хорошего кода с самого первого дня
Если вы следуете принципу единственной ответственности (SOLID: S — Single Responsibility) во время разработки, то скорее всего ситуация с дублированием кода не возникнет априори. Потому что вы изначально будете проектировать код так, что он будет хорошо разделён по программным единицам (методам, классам, модулям, библиотекам, микросервисам, системам и так далее).
Если мне нужно написать какую-то новую логику, разработать функционал и так далее, то первый вопрос, который я задаю себе: «а есть ли у нас уже эта логика где-то в коде?». Может быть так, что часть логики уже реализована или какие-то небольшие кусочки кода, которые можно переиспользовать, уже есть.
Если мы в своём коде поддерживаем хорошую структуру, всё раскладываем по пакетам, понятным директориям, то и найти уже готовые функции и методы будет относительно несложно. В любом случае, обычный поиск по Ctrl+F тоже очень хорошо выручает.
Использовать инструменты для поиска дублирований
У нас есть возможность многоуровневой проверки кода на дублирования:
- В среде разработки во время написания кода. Например, в IntelliJ IDEA есть встроенное средство для выявления дублирований;
- Во время сборки проекта. Например, есть плагин для Maven, который может фейлить билд, если в коде есть дублирования выше определённого порога;
- Во время CI/CD. Здесь можно использовать те же Maven-плагины, так как во время CI/CD мы тоже делаем сборку. Ещё один хороший инструмент — SonarQube.
Анализатор кода IntelliJ IDEA
Самый первый уровень защиты от дублирования кода — это встроенный в IntelliJ IDEA инспектор кода. Выглядит это вот так на практике:
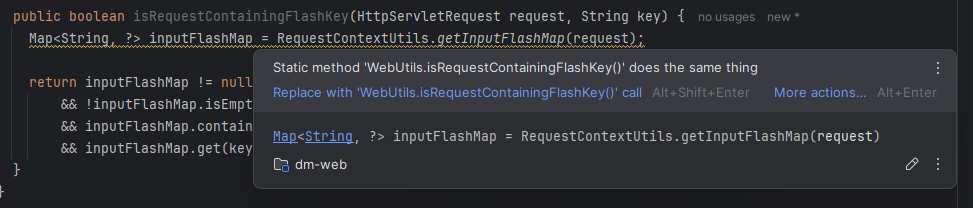
Встроенный анализатор кода подчёркивает части кода, которые вызывают у него сомнение. При наведении курсором
мыши на такой код мы можем увидеть подсказки. Например, в этом случае IntelliJ IDEA подсказывает, что у нас уже
есть метод в классе WebUtils, который делает в точности то же самое. А значит, можно удалить
этот метод-дубликат и использовать метод из WebUtils.
Автоматические анализаторы во время сборки
Но что, если мы пока писали код не заметили всех подсказок от IntelliJ IDEA анализатора? Такое возможно, потому что мы люди. Здесь к нам на помощь приходят средства автоматического поиска дубликатов. Если в качестве инструмента для сборки мы используем Maven, у нас есть два типа таких инструментов:
- Поиск повторяющегося кода — Copy/Paste Detection (выявление копипасты или точных повторений);
- Поиск повторяющихся классов, ресурсов или зависимостей.
О том как подключить их и настроить мы будем говорить в отдельной статье, посвящённой поддержке качества кода.
Сторонние инструменты для анализа кода
SonarQube по сути стал стандартом де-факто для анализа кода. Это облачное решение с бесплатным планом. О нём, его возможностях и о том, как его настроить, мы поговорим в отдельной статье, чтобы не перегружать эту.
А сейчас давайте наконец-то перейдём к практике, чтобы закрепить изученное на реальных примерах из жизни.
Практика: примеры «плохо» и «хорошо»
Spring Boot конфигурация
На первый взгляд пример ниже выглядит привычно и нормально:
links:
home: https://example.com
contacts: https://example.com/contacts
legal: https://example.com/terms-and-conditions
Но что будет, если по какой-то причине нам нужно будет переехать на другой домен? Нам нужно будет обновить адрес домена в трёх местах — не в одном. Да, переезд на другой домен — очень редкое событие. Но ведь и на месте домена может быть любая другая повторяющаяся информация.
Spring Boot позволяет нам писать вот так:
links:
home: https://example.com
contacts: ${links.home}/contacts
legal: ${links.home}/terms-and-conditions
YAML-резолвер Spring проходит через файл, парсит его содержимое. То есть во время подхода к строкам 3 и 4
у него уже будет значение из строки 2, и он сможет его подставить. Это значение из внутреннего состояния можно
получить по ключу links.home, что мы и делаем. Таким образом Spring позволяет переиспользовать
ранее определённые значения в других местах, избегая дублирования.
Давайте посмотрим на другой, более очевидный тип дубликата в конфигурации:
external:
order-service:
base-url: http://order-service.local:9001
timeout: 5000
payment-service:
base-url: http://payment-service.local:9001
timeout: 5000
fulfillment-service:
base-url: http://fulfillment-service.local:9001
timeout: 5000
Представим, что у нас микросервисная архитектура и наш микросервис делает запросы на три других микросервиса, чтобы создать заказ, обработать платёж и отправить его в службу исполнения заказов. Мы указываем базовые URL сервисов и таймауты для запросов. В этом примере дублирование таймаута может быть оправданным только если мы планируем задавать разные таймауты для разных сервисов. Но пока это не так — мы можем сделать вот так:
external:
timeout: 5000
order-service:
base-url: http://order-service.local:9001
timeout: ${external.timeout}
payment-service:
base-url: http://payment-service.local:9001
timeout: ${external.timeout}
fulfillment-service:
base-url: http://fulfillment-service.local:9001
timeout: ${external.timeout}
statistics-service:
base-url: http://statistics-service.us-east-1.local:8085
timeout: 7000
Мы просто выносим значение по умолчанию выше по дереву и ссылаемся на него во всех сервисах.
external.timeout мы можем рассматривать как значение по умолчанию для всех сервисов. Если для
какого-то из сервисов нужно будет позже переопределить это значение, мы просто можем для него прописать его
явно — как мы сделали это для statistics-service с таймаутом 7000.
Методы-дубликаты
Мы пишем код OrderService и добавляем в него метод calculateDiscount(). Проходит
время и мы пишем PaymentService, и по логике нам нужен метод для расчёта дискаунта — и мы снова
пишем calculateDiscount(), забыв, что он у нас уже есть. Так бывает в реальной жизни.
Получается вот так:
OrderService.java
@Service
public class OrderService {
// order related logic
private BigDecimal calculateDiscount(Order order) {
if (order.getAmount().compareTo(new BigDecimal("100")) > 0) {
return order.getAmount().multiply(new BigDecimal("0.1"));
}
return BigDecimal.ZERO;
}
}
PaymentService.java
@Service
public class PaymentService {
// payment related logic
private BigDecimal calculateDiscount(Order order) {
if (order.getAmount().compareTo(new BigDecimal("100")) > 0) {
return order.getAmount().multiply(new BigDecimal("0.1"));
}
return BigDecimal.ZERO;
}
}
Решений здесь может быть несколько. Нам нужно посмотреть на метод и решить — за что он отвечает, и входит ли
эта ответственность в логику работы с заказом (OrderService) либо в логику работы с платежом
(PaymentService).
Лично я решил, что эта логика является отдельной независимой ответственностью и может быть вынесена в
отдельный, независимый компонент — DiscountCalculator:
@Component
public class DiscountCalculator {
private BigDecimal calculate(Order order) {
if (order.getAmount().compareTo(new BigDecimal("100")) > 0) {
return order.getAmount().multiply(new BigDecimal("0.1"));
}
return BigDecimal.ZERO;
}
}
А OrderService и PaymentService теперь просто вызывают этот компонент в своём коде.
Дублирование части логики
Посмотрим на эти два метода в сервисе. Один экспортирует отчёт в формате CSV, а другой — в формате JSON:
@Service
public class ReportService {
private final ReportRepository reportRepository;
public ReportService(ReportRepository reportRepository) {
this.reportRepository = reportRepository;
}
public String exportReportAsCsv(long reportId) {
Report report = reportRepository.findById(reportId)
.orElseThrow(() -> new ReportNotFoundException(reportId));
if (!report.isReady()) {
throw new ReportNotReadyException(reportId);
}
List<ReportRow> rows = reportRepository.fetchRows(reportId);
if (rows.isEmpty()) {
throw new EmptyReportException(reportId);
}
// специфическая логика CSV
StringBuilder csv = new StringBuilder();
for (ReportRow row : rows) {
csv.append(row.getName())
.append(",")
.append(row.getAmount())
.append("\n");
}
return csv.toString();
}
public String exportReportAsJson(long reportId) {
Report report = reportRepository.findById(reportId)
.orElseThrow(() -> new ReportNotFoundException(reportId));
if (!report.isReady()) {
throw new ReportNotReadyException(reportId);
}
List<ReportRow> rows = reportRepository.fetchRows(reportId);
if (rows.isEmpty()) {
throw new EmptyReportException(reportId);
}
// специфическая логика JSON
StringBuilder json = new StringBuilder("[");
for (int i = 0; i < rows.size(); i++) {
ReportRow row = rows.get(i);
json.append("{")
.append("\"name\":\"").append(row.getName()).append("\",")
.append("\"amount\":").append(row.getAmount())
.append("}");
if (i < rows.size() - 1) {
json.append(",");
}
}
json.append("]");
return json.toString();
}
}
Казалось бы, два разных формата отчётов — два разных метода. И да — это нормально. Но есть одно «но»: перед основной логикой, специфичной для каждого метода, мы выполняем необходимые проверки. И эти проверки абсолютно идентичны в обоих методах. То есть если нам в какой-то момент нужно будет обновить код проверки — нам нужно будет сделать это в двух местах сразу. А если забудем, то методы перестанут быть согласованными с точки зрения логики валидации.
А теперь исправленная версия того же сервиса:
@Service
public class ReportService {
private final ReportRepository reportRepository;
public ReportService(ReportRepository reportRepository) {
this.reportRepository = reportRepository;
}
public String exportReportAsCsv(long reportId) {
List<ReportRow> rows = loadReportRows(reportId);
StringBuilder csv = new StringBuilder();
for (ReportRow row : rows) {
csv.append(row.getName())
.append(",")
.append(row.getAmount())
.append("\n");
}
return csv.toString();
}
public String exportReportAsJson(long reportId) {
List<ReportRow> rows = loadReportRows(reportId);
StringBuilder json = new StringBuilder("[");
for (int i = 0; i < rows.size(); i++) {
ReportRow row = rows.get(i);
json.append("{")
.append("\"name\":\"").append(row.getName()).append("\",")
.append("\"amount\":").append(row.getAmount())
.append("}");
if (i < rows.size() - 1) {
json.append(",");
}
}
json.append("]");
return json.toString();
}
private List<ReportRow> loadReportRows(long reportId) {
Report report = reportRepository.findById(reportId)
.orElseThrow(() -> new ReportNotFoundException(reportId));
if (!report.isReady()) {
throw new ReportNotReadyException(reportId);
}
List<ReportRow> rows = reportRepository.fetchRows(reportId);
if (rows.isEmpty()) {
throw new EmptyReportException(reportId);
}
return rows;
}
}
Теперь общий код находится в одном единственном методе loadReportRows(). Такой код стало проще
поддерживать: каждый метод содержит логику в одном единственном экземпляре. Такой код ещё и стал короче и
компактнее, тем самым снизив нагрузку на мозг. Больше кода — больше нужно просмотреть глазами и обдумать.
А теперь два важных момента
На фоне всего вышесказанного важно упомянуть о двух интересных моментах, которые нужно понимать, когда говорим про дублирование кода.
Дублирующая логика — не то же самое, что похожая логика
У нас могут быть два очень похожих метода в одном классе. Похожих с точки зрения кода. Но не одинаковых. И самое главное — выполняющих разную бизнес-логику. Такие методы не являются дублирующими и такие методы не нужно пытаться приводить к одному виду и объединять в один. Это не про дублирование. Это просто про похожесть кода и не более. Посмотрим на несколько примеров.
Разные бизнес-правила для скидок
Расчёт скидки для обычного клиента и для VIP-клиента выглядит практически одинаково:
Расчёт скидки — обычный клиент
public BigDecimal calculateRegularCustomerDiscount(Order order) {
if (order.getAmount().compareTo(new BigDecimal("100")) > 0) {
return order.getAmount().multiply(new BigDecimal("0.05"));
}
return BigDecimal.ZERO;
}
Расчёт скидки — VIP клиент
public BigDecimal calculateVipCustomerDiscount(Order order) {
if (order.getAmount().compareTo(new BigDecimal("100")) > 0) {
return order.getAmount().multiply(new BigDecimal("0.10"));
}
return BigDecimal.ZERO;
}
На первый взгляд разница здесь лишь в проценте скидки: для обычного клиента она составляет 5%, для VIP — 10%. И как будто мы могли бы объединить расчёт в один общий метод, а процент вынести в файл конфигурации:
application.yaml
discount:
regular: 0.05
vip: 0.10
Конфигурационный класс
@ConfigurationProperties(prefix = "discount")
public class DiscountProperties {
private BigDecimal regular;
private BigDecimal vip;
// getters/setters
}
Общий метод
public BigDecimal calculateDiscount(Order order, CustomerType customerType) {
BigDecimal discount = switch (customerType) {
case REGULAR -> discountProperties.getRegular();
case VIP -> discountProperties.getVip();
};
if (order.getAmount().compareTo(new BigDecimal("100")) > 0) {
return order.getAmount().multiply(discount);
}
return BigDecimal.ZERO;
}
Как видите, сейчас всё выглядит отлично с точки зрения DRY: нет дублирования кода, конфигурация вынесена в отдельный файл. Но это ловушка. Здесь мы смешали алгоритмы расчётов двух разных типов клиентов в один метод, которые могут быть разными и в любой момент могут измениться.
И далее пример из реальной жизни — приходит новое бизнес-требование:
Для обычных клиентов:
- скидка 5%
- только если сумма заказа более 200 у.е.
Для VIP клиентов:
- скидка 10% при заказе на более чем 100 у.е.
- скидка 15% при заказе на более чем 500 у.е.
И здесь начинается самое интересное — мы начинаем усложнять наш «универсальный» метод, добавляя в него новые бизнес-правила:
public BigDecimal calculateDiscount(Order order, CustomerType customerType) {
BigDecimal amount = order.getAmount();
if (customerType == CustomerType.REGULAR) {
if (amount.compareTo(new BigDecimal("200")) > 0) {
return amount.multiply(discountProperties.getRegular());
}
return BigDecimal.ZERO;
}
if (customerType == CustomerType.VIP) {
if (amount.compareTo(new BigDecimal("500")) > 0) {
return amount.multiply(new BigDecimal("0.15"));
}
if (amount.compareTo(new BigDecimal("100")) > 0) {
return amount.multiply(discountProperties.getVip());
}
return BigDecimal.ZERO;
}
return BigDecimal.ZERO;
}
Но что будет, если придёт новое требование, где нужно будет добавить новый тип клиента — например,
PREMIUM? Логика нашего метода ещё больше «раздуется». Здесь уже налицо нарушение принципа
единственной ответственности (SOLID, «S» — Single Responsibility), потому что один метод делает расчёты
для разных типов клиентов.
Если бы мы оставили логику в двух отдельных методах, то сейчас это выглядело бы вот так — чисто и понятно:
Обычный клиент — после изменений
public BigDecimal calculateRegularCustomerDiscount(Order order) {
BigDecimal amount = order.getAmount();
if (amount.compareTo(new BigDecimal("200")) > 0) {
return amount.multiply(new BigDecimal("0.05"));
}
return BigDecimal.ZERO;
}
VIP клиент — после изменений
public BigDecimal calculateVipCustomerDiscount(Order order) {
BigDecimal amount = order.getAmount();
if (amount.compareTo(new BigDecimal("500")) > 0) {
return amount.multiply(new BigDecimal("0.15"));
}
if (amount.compareTo(new BigDecimal("100")) > 0) {
return amount.multiply(new BigDecimal("0.10"));
}
return BigDecimal.ZERO;
}
То есть каждый метод отвечает исключительно за свой расчёт и ни за что другое. Single Responsibility соблюдён, архитектура чистая и ясная, легко вносить новые изменения. Если у нас появится новый тип клиента, мы просто добавим ещё один метод и напишем в нём свою логику.
Интерфейс
public interface DiscountCalculator {
BigDecimal calculate(Order order);
}
RegularDiscountCalculator.java
public class RegularDiscountCalculator implements DiscountCalculator {
public BigDecimal calculate(Order order) {
if (order.getAmount().compareTo(new BigDecimal("200")) > 0) {
return order.getAmount().multiply(new BigDecimal("0.05"));
}
return BigDecimal.ZERO;
}
}
VipDiscountCalculator.java
public class VipDiscountCalculator implements DiscountCalculator {
public BigDecimal calculate(Order order) {
BigDecimal amount = order.getAmount();
if (amount.compareTo(new BigDecimal("500")) > 0) {
return amount.multiply(new BigDecimal("0.15"));
}
if (amount.compareTo(new BigDecimal("100")) > 0) {
return amount.multiply(new BigDecimal("0.10"));
}
return BigDecimal.ZERO;
}
}
Всё чисто и ясно. Если у нас появился новый тип клиента — мы просто добавим ещё один новый класс-компонент.
Валидация в разных контекстах
У нас есть метод валидации электронной почты во время регистрации нового пользователя и метод валидации перед отправкой уведомления клиенту. В начале они выглядят абсолютно одинаково:
Валидация email для регистрации
public void validateEmailForRegistration(String email) {
if (email == null || !email.contains("@")) {
throw new IllegalArgumentException("Invalid email address");
}
}
Валидация email для уведомления
public void validateEmailForNotification(String email) {
if (email == null || !email.contains("@")) {
throw new IllegalArgumentException("Invalid email address");
}
}
Код обоих методов абсолютно идентичен и как будто их можно было бы объединить. Но он вызывается в разных контекстах, а значит, в будущем, код обоих методов может иметь разную логику. Вот реалистичный пример таких расхождений:
Валидация email — регистрация (полная версия)
public void validateEmailForRegistration(String email) {
if (email == null || email.isBlank()) {
throw new IllegalArgumentException("Email must be provided for registration");
}
if (!email.contains("@")) {
throw new IllegalArgumentException("Invalid email format");
}
if (email.length() > 254) {
throw new IllegalArgumentException("Email is too long");
}
if (userRepository.existsByEmail(email)) {
throw new IllegalArgumentException("Email is already registered");
}
}
Валидация email — уведомление (полная версия)
public void validateEmailForNotification(String email) {
if (email == null || email.isBlank()) {
throw new IllegalArgumentException("Email must be provided to send notification");
}
if (!email.contains("@")) {
throw new IllegalArgumentException("Invalid email format");
}
User user = userRepository.findByEmail(email)
.orElseThrow(() -> new IllegalArgumentException("User with this email does not exist"));
if (!user.isEmailVerified()) {
throw new IllegalArgumentException("Cannot send notification to unverified email");
}
if (!user.isSubscribedToNotifications()) {
throw new IllegalArgumentException("User is not subscribed to notifications");
}
}
Мы не можем регистрировать клиента, который уже есть в базе данных. И наоборот — мы не можем отправить уведомление клиенту, которого нет в базе данных. Так методы, которые поначалу казались дублями, превращаются в самостоятельную, независимую логику с разными бизнес-правилами.
Логические дублирования не будут найдены анализаторами кода
Анализаторы кода могут помогать нам выявлять дублирующийся код по заданным правилам и критериям. Но как мы говорили в самом начале статьи, DRY — это про дублирование знаний, а не кода. Часто вместе со «знаниями» дублируется и код, но не всегда. И это важно понимать. Посмотрим на такой пример.
Представим, что в нашей системе есть бизнес-правило, которое определяет является ли заказ большим, основываясь на сумме 1000 у.е. И представим, что в нашем коде есть три разных метода в трёх разных сервисах:
// OrderService
public boolean isLargeOrder(Order order) {
return order.getTotalAmount().compareTo(new BigDecimal("1000")) > 0;
}
// ReportService
public boolean isLargeOrder(Order order) {
BigDecimal threshold = BigDecimal.valueOf(1000);
if (order.getTotalAmount().compareTo(threshold) == 1) {
return true;
}
return false;
}
// DiscountService
public boolean isLargeOrder(Order order) {
double amount = order.getTotalAmount().doubleValue();
return amount > 1000.0;
}
Если всмотреться в логику каждого из этих трёх методов, то все они по сути делают одно и то же. Но каждый из них реализован по-своему. Это создаёт дубли кода, которые сложно найти и выявить. В нашем случае все три метода имеют одинаковые сигнатуры, но в реальности и они могут отличаться.
Теперь посмотрим на правильную реализацию — выносим логику в отдельный класс:
public class OrderRules {
private static final BigDecimal LARGE_ORDER_THRESHOLD = new BigDecimal("1000");
public static boolean isLargeOrder(Order order) {
return order.getTotalAmount().compareTo(LARGE_ORDER_THRESHOLD) > 0;
}
}
Во всех трёх сервисах используем таким образом:
if (OrderRules.isLargeOrder(order)) {
// your logic here
}
Теперь вся логика в одном месте. Архитектура стала чистой, очевидной и хорошо поддерживаемой. Но как избежать проблем с неявным дублированием логики?
- Code Review — когда внутри команды вы ревьювите друг друга. Такой подход помогает найти проблемы, которые ты мог не заметить пока писал код. Это общеизвестная практика и скорее всего вы на проекте уже делаете это;
- Архитектурный анализ — ты и/или lead вашей команды можете время от времени делать анализ кода вашего сервиса или системы. Идея в том, чтобы найти проблемы в коде, в числе которых и дублирующаяся логика.
Но что делать, чтобы такие скрытые дубли даже не возникали? Здесь важно задавать себе вопрос каждый раз, прежде чем добавить новую логику в проект: «А есть ли эта логика уже где-то в проекте?». Если не нашли — пишем новую. Если нашли — переиспользуем.
Совет для тех, кто использует нейросети для генерации кода
В последнее время мы часто прибегаем к помощи нейросетей для написания кода бизнес-логики. На самом деле, это хорошо и такой подход ускоряет разработку — но только в том случае, когда вы понимаете, что делаете, и просто хотите ускорить разработку, отдавая нейросети чёткие команды. Так, как если бы вы просили своего Junior-разработчика в команде реализовать ту или иную логику.
Но что здесь ещё важно. Вы ведь потом ревьювите код своего младшего помощника? Вы пытаетесь полностью понять, что написал ваш коллега, вы пытаетесь найти изъяны или проблемы, если они есть. То же самое применимо к коду, который написала для вас нейросеть.